Let’s take a quick end-to-end look at how to convert data from one format to another using AWS Glue, then query that data using AWS Athena.
You can download the file used in this tutorial from Kaggle’s dataset repository (https://www.kaggle.com/datasets/swathiunnikrishnan/amazon-consumer-behaviour-dataset).
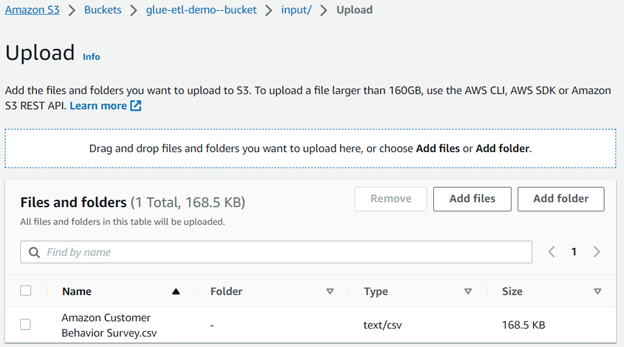
Step 1: Start by uploading your data to an S3 bucket on AWS. You can either use the sample file provided or your own data.
Step 2: Open the AWS Management Console and search for AWS Glue. Create a crawler in Glue to gather metadata about the data. You also have the option to create a new database, which serves as a data catalog for storing schema information.

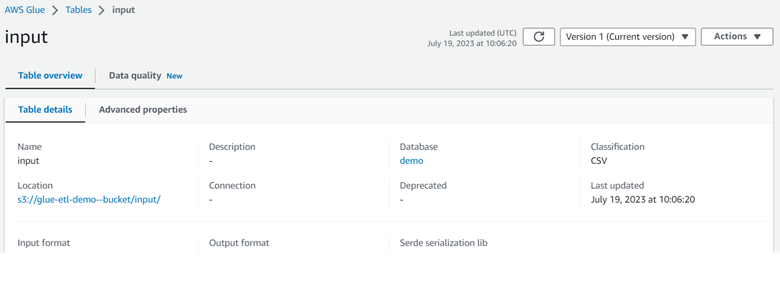
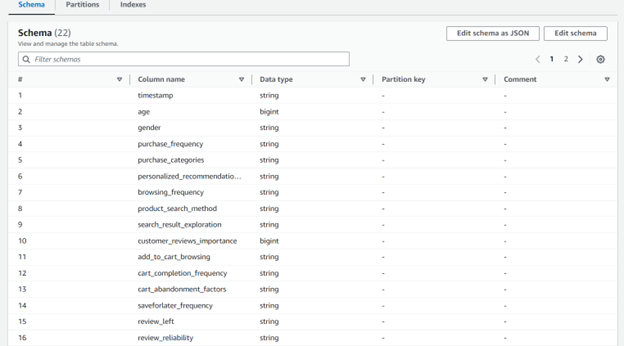
Step 3: Run the crawler in Glue, which will quickly analyze the data and determine its schema.
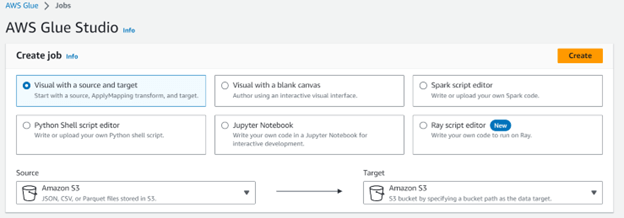
Step 4: Proceed to create an ETL (Extract, Transform, Load) job in Glue to convert the data from CSV format to columnar data in Parquet format. Navigate to the Jobs section in the Glue console and create a new job using the visual interface.
Step 5: Select the input bucket for the job and allow Glue to infer the schema based on the crawled metadata.
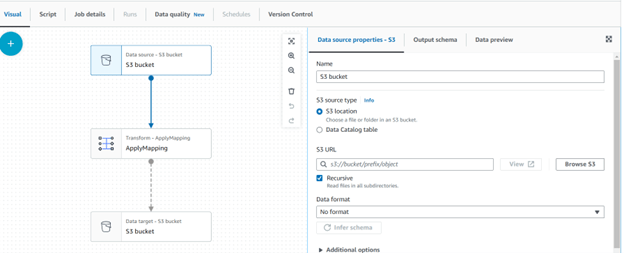
Step 6: In the apply mapping step of the job, you can modify the schema data types if necessary. For example, you can change the age data type to an integer.
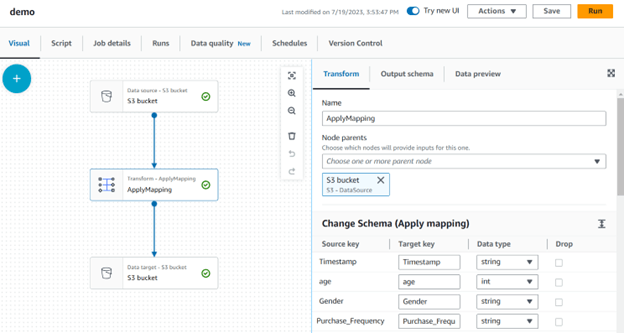
Step 7: Within the visual script of the job, you can add various nodes to perform different transformations such as selecting specific fields, dropping unnecessary fields, removing duplicates, and more.
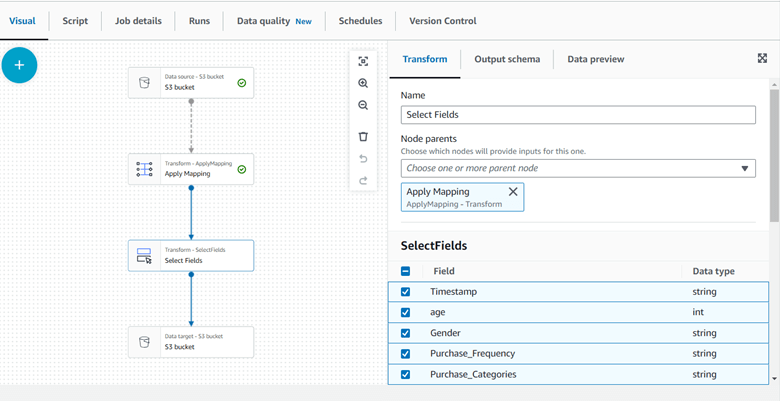
In your case, you have chosen the select fields node to specify the desired fields for the output table. Make sure to select the appropriate node parent, which in this case is the Apply Mapping node.
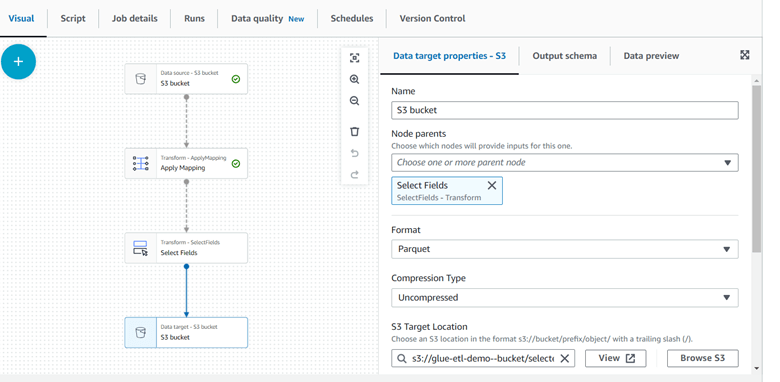
Step 8: Choose the destination folder for the transformed data and specify the output file format as Parquet. You also have the option to select the desired compression type.
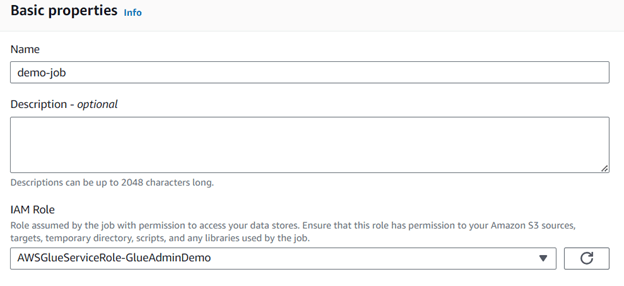
Step 9: Provide a name and role for the job. The IAM role you specify must have the necessary permissions to access both the S3 bucket containing the data and the Glue service. Save the job configuration and then run it.
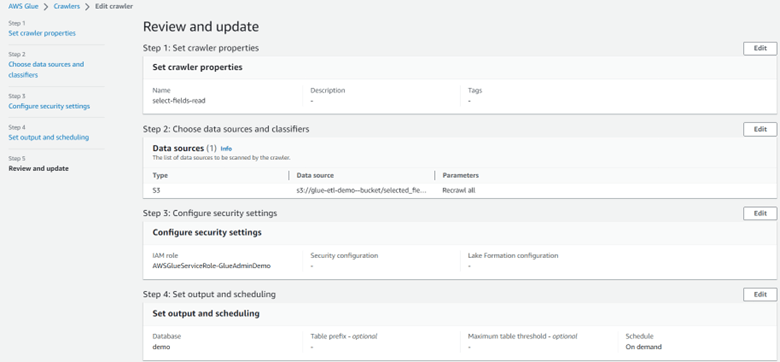
Step 10: Once the job has completed successfully, create another crawler in Glue to crawl and update the metadata for the newly generated Parquet file.
Step 11: Now you can use Amazon Athena to query the data. Athena allows you to run SQL queries against the data stored in the S3 bucket, providing you with fast and interactive analysis capabilities.

Step 12: Once completed with the tutorial make sure to clean up the resources that were used in this tutorial.
Thank You!!!
Anushka Kokate
Data Engineering
Addend Analytics