


At Addend Analytics, we’ve noticed some client misunderstanding about when Azure SQL Data Warehouse is the best option. This blog post and the decision tree that follows it are intended to assist you in answering the following question: Is Azure SQL Data Warehouse the most appropriate technology for your project?
Microsoft’s Azure SQL Data Warehouse (SQL DW) is a cloud-based Platform-as-a-Service (PaaS) solution. It’s a large-scale, distributed MPP (massively parallel processing) relational database system that competes with Amazon Redshift and Snowflake. The Modern Data Warehouse multi-platform architecture relies heavily on Azure SQL DW. Azure SQL DW is designed for large-scale analytical workloads that can benefit from parallelism because it is an MPP system with a shared-nothing architecture across distributions. Azure SQL DW’s distributed nature allows storage and computing to be divorced, allowing for independent pricing and scalability. Because its compute power may be ramped up, down, or even halted to reserve (and pay for) the amount of compute resources required to handle the workload, Azure SQL DW is considered an elastic data warehouse.
Microsoft’s Azure SQL DW is part of the ‘SQL Server family,’ which also includes Azure SQL Database and SQL Server (both of which are SMP, symmetric multiprocessing, architecture). Because of this similarity, knowledge and experience from Azure SQL Database and SQL Server will transfer well to Azure SQL DW, with one notable exception: MPP architecture is very different from SMP architecture in Azure SQL Database and SQL Server, necessitating specific design techniques to fully exploit the MPP architecture. The rest of this essay goes over some of the most critical aspects to think about while deciding whether or not to use Azure SQL DW.
Enterprise BI with SQL Data Warehouse and Azure Data Factory
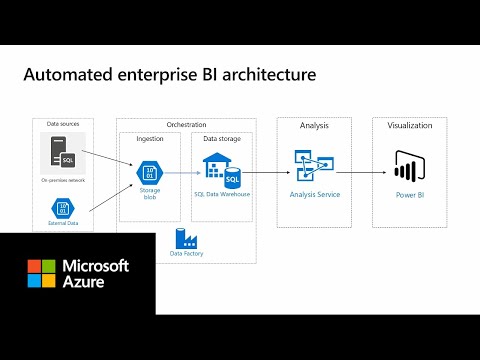
Each of the items in the decision tree above is highlighted in the following comments:
Q1: Have you justified that a relational data warehouse solution is supported by business requirements and needs?
The following are some of the most prevalent justifications for implementing a data warehouse:
Consolidate and relate multiple disparate data sources
When data from numerous sources is combined, it becomes naturally more useful. The 360-degree picture of a customer, for example, might synchronise customer master data, sales, open receivables, and support requests so that they can all be examined simultaneously.
Centralize analytical data for user data access
The most common perception of a data warehouse is that it aids corporate business intelligence initiatives (typically thought of as standardised corporate reports and dashboards). It can also help with self-service BI by delivering data that is consistent, cleansed, and controlled. Although achieving a “single version of the truth” may never be 100% possible, proper governance and master data management can raise the likelihood that the data warehouse will deliver consistent and reliable data for all sorts of analytics across the enterprise.
Historical analysis
Techniques like periodic snapshots and slowly changing dimensions are used in the data warehouse to support historical reporting and analysis. A common scenario is that a customer’s sales representative has changed this quarter, or that a department has been transferred to another division. The ability to report on “the way it was” or “the way it is” might be quite valuable – and it’s something that’s rarely available from traditional source systems.
User-friendly data structure
It is beneficial to organise the data into a user-friendly dimensional model that benefits the majority of the user base. Other strategies that contribute to ease of use include friendly table and column names, derived attributes, and useful metrics (such as MTD, QTD, and YTD). Time investments in this area should encourage data analysts to use the data warehouse, resulting in consistent results and, as a result, time and effort savings.
Minimize silos
When a business-driven analytical solution (also known as shadow IT) becomes vital to the operation of the company, it’s time to move it to a centralised system where it can be better supported, connected with other data, and made available to a larger user base. The data warehouse can benefit from the efforts of business users to grow in maturity and value while reducing silos and “one-off” solutions.
Multi-platform architecture which takes advantage of existing investment
It is not economically possible to retire or transfer everything to a new architecture if your present data warehouse provides value for certain use cases (ex: Hadoop or data lake). Instead, we advocate a multi-platform architecture in which the data warehouse is just one component, albeit one that is critical. For example, leveraging a data lake for data input, exploratory analysis, staging for a data warehouse, and/or archival from the data warehouse are all useful additions to a data warehouse that may serve much of the curated, cleansed data.
Tip: A data warehouse is most useful when used in conjunction with other services, such as a data lake, so that each service may focus on its strengths.
Q2: Are you comfortable with a cloud-based Platform-as-a-Service solution?
Azure SQL DW is a public cloud and national (sovereign) cloud service offering. It’s a PaaS (Platform-as-a-Service) solution in which the customer has no control over the underlying server architecture and has no visibility into it. Azure SQL DW’s storage and computing are detached, which is a significant benefit. Processing power (compute) costs are calculated using a consumption model that is managed by data warehouse units (DWUs for Gen1 and cDWUs for Gen2) that can be scaled to handle high data loads and peak user volumes. The persisted data must be stored on Azure premium storage, which is more expensive than regular storage but performs better.
Tip: Microsoft manages system updates as a PaaS service. Customers can choose a preferred primary and secondary day/time range for system maintenance in Azure SQL DW.
Q3: What kind of workload do you have?
Analytical workloads, such as batch-oriented, set-based read and write operations, are best served by Azure SQL DW. Transactional workloads (i.e., numerous little read and write operations) and workloads with many row-by-row operations are not suited.
Tip: Although the term “data warehouse” is included in the product name, Azure SQL Database can be used for a smaller-scale data warehousing workload if Azure SQL DW is not justified. Keep in mind that while Azure SQL DW is part of the SQL Server family, there are some differences in limits and features between Azure SQL DW, Azure SQL DB, and SQL Server.
Q4: How large is your database?
The ultimate minimum size advised for Azure SQL DW is difficult to nail down with precision. Many industry experts believe that the minimum “realistic” data size for Azure SQL DW is in the range of 1-4 TB. Because Azure SQL DW is an MPP (massively parallel processing) system, the expense incurred to distribute and condense data across the nodes (which are distributions in a “shared nothing” design) has a large performance penalty with small data quantities. For a data warehouse that is approaching 1 TB in size and is likely to grow, we recommend Azure SQL DW.
Tip: When considering whether or not to use Azure SQL DW, it’s critical to consider realistic future growth. Because the data load patterns for Azure SQL DW (which uses PolyBase and techniques like CTAS to improve MPP performance) differ from those for Azure SQL DB or SQL Server, it could be a good idea to start with Azure SQL DW to avoid a future migration and effort spent developing data load processes. However, it is a fallacy that you can provision the smallest size Azure SQL DW and expect it to operate identically to Azure SQL DB.
Q5: Do you have firm RPO, RTO, or backup requirements?
Azure SQL DW, being a PaaS product, performs daily snapshots and backups. Over the preceding 7 days, the service automatically builds restore points throughout the day and supports an 8-hour recovery point objective (RPO). The service also automatically creates a geo-redundant backup once a day, with a recovery point goal of 24 hours. Customers can also create a user-defined restore point at any point in time. A user-defined restore point has a 7-day retention period after which it is automatically erased.
Tip: When the compute resources for Azure SQL DW are suspended, backups are not taken.
Q6: Do you plan to deliver a multi-tenant data warehouse?
With Azure SQL DW, a multi-tenancy database design pattern is often prohibited.
Tip: Although multi-tenancy features such as row-level and column-level security are available, you might want to consider using elastic pools in conjunction with Azure SQL Database for multi-tenancy applications instead.
Q7: What kind of data model represents your data warehouse?
The use of Azure SQL DW is not fully barred by a highly normalised data warehouse structure. Azure SQL DW, on the other hand, performs significantly better with denormalized data structures since it makes extensive use of clustered column store indexes (which employ columnar compression techniques). As a result, adhering to sound dimensional design standards is strongly recommended.
Modern reporting technologies are more tolerant of poor data models, prompting some data warehouse engineers to relax their dimensional design standards. This is a problem, especially if there are a lot of people submitting self-service questions, because a well-formed star schema greatly improves usability.
Q8: How is your data dispersed across tables in the database?
Table distribution is an important aspect even if you have a huge database (1-4 TB+). Fewer, larger tables (1 billion+ rows) perform better on an MPP system like Azure SQL DW than numerous tiny to medium-sized databases (less than 100 million rows).
Tip: A table does not benefit from being classified as a clustered column store index until it contains more than 60 million rows, as a rule of thumb (60 distributions x 1 million rows each). We want to make every effort in Azure SQL DW to make clustered column store indexes (CCIs) as effective as possible. There are a few reasons for this, but one of the most important is that CCI data is stored on local SSDs, and retrieving data from cache dramatically improves performance (applicable to Azure SQL DW Gen2 only).
Q9: Do you understand your data loading and data consumption patterns extremely well?
Azure SQL DW is considered “schema on write” because it is a relational database. Because Azure SQL DW is a distributed system, distribution keys tell the system how to divide data between nodes. The choice of an appropriate distribution key is crucial for large table performance. In addition to data distribution, Azure SQL DW and conventional SQL Server have various partitioning algorithms. To maximise parallelization, reduce data skew, and minimise data movement operations and shuffling inside the MPP platform, Azure SQL DW developers must have a thorough understanding of data load patterns and query patterns.
Tip: PolyBase can be used in one of two ways: (1) to load data into Azure SQL DW (which is highly recommended), or (2) to query remote data not stored in Azure SQL DW. Because it can naturally take use of the parallelization of the compute nodes, PolyBase is the recommended method for loading data in Azure SQL DW, whereas alternative loading approaches do not perform as well because they go through the control node. PolyBase should be used with caution when searching remote data (see Q15 below).
Q10: Are you comfortable with ELT vs. ETL data load patterns, and with designing data load operations to specifically take advantage of distributed, parallel processing capabilities?
A distributed MPP system’s loading principles and patterns differ significantly from a standard SMP (Symmetric Multi-Processing) system. PolyBase and ELT (extract>load>transform) approaches are recommended for Azure SQL DW data load procedures to take advantage of parallelization across compute nodes. This implies that migrating to Azure SQL DW frequently necessitates reworking existing ETL operations to improve performance, reduce logging, and/or take use of supporting features (for example, merge statements are not currently supported in SQL DW; there are also limitations with respect to how insert and delete operations may be written; using CTAS techniques are recommended to minimise logging). Iterative efforts to discover the appropriate distribution technique for new tables introduced to Azure SQL DW are common.
Tip: PolyBase might be difficult to work with depending on the data source format and data contents, despite the fact that it considerably improves data load performance due to parallelization (for instance, when commas and line breaks appear within the data itself). Make sure you leave enough time in your project schedule to develop and test the new data load design patterns.
Q11: Do you have staff to manage, monitor, and tune the MPP environment?
Despite the fact that Azure SQL DW is a PaaS platform, it should not be considered a hands-off environment. Monitoring data loads and query demands is required to assess whether distribution keys, partitions, indexes, and statistics are properly configured.
Tip: There are some new capabilities in Azure SQL DW that make recommendations. Integration with Azure Advisor and Azure Monitor is always improving, making it easier for administrators to spot problems. Azure SQL DW Gen2 uses Azure Advisor’s “automated intelligent insights” to show if there are any issues with data skew, missing statistics, or obsolete statistics.
Q12: Do you have a low number of concurrent query users?
If the maximum concurrency level is surpassed, requests are queued up and resolved in a first-in-first-out fashion. Azure SQL DW frequently provides complimentary solutions in a multi-platform architecture for managing different types of query demands due to concurrent user concerns. In a hub-and-spoke arrangement, Azure Analysis Services and/or Azure SQL Database are frequently used as spokes.
Tip: Depending on the service tier (i.e., the billing level) and resource class consumption, the number of concurrent queries that can run at the same time can be as high as 128. (Because assigning more resources to a specific user reduces the overall number of concurrency slots available)
Q13: Do you have a lot of self-service BI users sending unpredictable queries?
A data warehouse’s main purpose is to provide data for massive searches. Although a product like Power BI allows for direct querying of Azure SQL DW, this should be done with caution. Dashboards, in particular, can be problematic because a dashboard page refresh can send a large number of queries to the data warehouse all at once. As mentioned in Q12, we frequently recommend adding a semantic layer, such as Azure Analysis Services, as part of a hub-and-spoke architecture when using Power BI in production. The goal of adding a semantic layer is to (a) reduce query demand on the MPP (by reducing data movement when unexpected queries arrive), (b) reduce concurrent queries executed on the MPP system, and (c) include user-friendly calculations and measures that can dynamically respond as a user interacts with a report.
Tip: It is undoubtedly possible to use Azure SQL DW in conjunction with a business intelligence solution like as Power BI (i.e., with Power BI operating in DirectQuery mode rather than import mode). However, if the user base demands sub-second speed when slicing and dicing, DirectQuery mode should be properly verified. If, on the other hand, more data exploration is required and query response time is more flexible, direct querying of Azure SQL DW from a tool like Power BI may be possible. Adaptive caching for tables defined as clustered column store indexes was introduced in Azure SQL DW’s Gen2 tier (CCI). Adaptive caching enhances performance by increasing the likelihood that self-service user queries can be met from cached data in Azure SQL DW. Another option to explore is Power BI Premium, which now includes aggregations that can cache data in Power BI’s in-memory model for the first level of queries, requiring a drillthrough to Azure SQL DW only when the user reaches a lower level or less frequently used data.
Q14: Do you have near-real-time data ingestion and reporting requirements?
Batch-oriented data load methods are most typically connected with distributed systems like Azure SQL DW. However, new features for near-real-time streaming data ingestion into Azure SQL DW continue to emerge. This works with Azure Databricks streaming dataframes, which opens up some exciting new possibilities for low-latency data analysis (such as data generated from IoT devices or the web).
Tip: When using Azure Databricks for streaming data, it serves as the front-end for the ingestion stream before being sent to Azure SQL DW in mini-batches via PolyBase—so it’s a near-real-time system, but there will be some delay. Additionally, keep in mind that Azure Databricks can be used as a data engineering tool for batch data processing and loading to Azure SQL DW (the JDBC Azure SQL DW connector from Azure Databricks does take advantage of PolyBase).
Q15: Do you have requirements for data virtualization in addition to or in lieu of data integration?
PolyBase in Azure SQL DW now supports Azure Storage (blobs) and Azure Data Lake Storage (Gen1 or Gen2) for very selective data virtualization and data federation. Data virtualization is the process of querying data regardless of where it is stored (thus saving work to do data integration to relocate the data elsewhere).
Tip: There is no pushdown computation to increase query performance when using PolyBase for data virtualization (i.e., querying remote data stored in Azure Storage or Azure Data Lake Storage). This indicates that in order to satisfy the query, Azure SQL DW must read the full file into TempDB. It is possible to use virtualized queries effectively in very specific situations where query response speed is not of utmost importance (such as a quarter-end analysis or data to supply to the auditors) for queries that are issued rarely (such as a quarter-end analysis or data to supply to the auditors).
Q16: Do you anticipate the need to integrate with multi-structured data sources?
A data warehouse is frequently used in conjunction with a data lake, which comprises multi-structured data from sources such as online logs, social media, IoT devices, and other sources. Although Azure SQL DW does not handle JSON, XML, spatial, or picture data formats, it can be used in conjunction with Azure Storage and/or Azure Data Lake Storage (Gen1 or Gen2) to provide more flexibility for data integration and/or data virtualization scenarios.
Tip: PolyBase now supports reading Parquet, Hive ORC, Hive RCFile, and delimited text (such as a CSV) formats when connecting to external data. One of the top candidates for a data lake storage format is Parquet.
Q17: Do you intend to scale processing power up, down, and/or pause to meet varying data load and/or query demands?
The elasticity of compute power is one of the best benefits of a cloud service like Azure SQL DW. For example, you could scale up on a timetable to support a high-volume data load, then scale back down when the load is finished. The Azure SQL DW can even be halted when no queries are made to the data warehouse at all, ensuring that data is stored safely while incurring no computation charges (because storage and compute are decoupled). Scale up/down/pause approaches can help you avoid over-provisioning of resources, which is a great way to save money.
Tip: All open sessions are stopped, and open insert/update/delete transactions are rolled back when a scaling up or down operation is initiated. This behaviour ensures that the Azure SQL DW remains stable during the update. The brief outage could not be acceptable for a production system, or it might only be allowed during certain business hours. Keep in mind that when a scale or halt happens, the adaptive cache (available with the Gen2 tier) is cleaned, requiring the cache to be re-warmed to achieve optimal performance.
Addend Analytics would be happy to assist you in determining the optimal data analytics architecture for your company’s needs. Contact us today to learn more about how our team creates solutions that are tailored to your company’s needs and budget.