By default, SQL is not case-sensitive; the use of capitalized letters in SQL queries typically follows a naming convention rather than influencing the query’s functionality. However, scenarios may arise where case sensitivity becomes crucial, particularly when dealing with data that holds distinct meanings based on the case. In such situations, we can leverage database collation to address this issue. Before delving into a solution, it’s essential to comprehend the concept of database collation.
In SQL Server, collation refers to a set of rules that determine how string comparison and sorting operations are performed. It encompasses considerations such as case sensitivity, accent sensitivity, and linguistic sorting rules. The collation settings are specified at various levels, including the server, database, and individual columns.
Collation Settings:
Collation settings can include options for case sensitivity (CS or CI), accent sensitivity (AS or AI), and width sensitivity (WS or WI). For example:
- CS (Case Sensitive): ‘A’ and ‘a’ are considered different.
- CI (Case Insensitive): ‘A’ and ‘a’ are considered the same.
- AS (Accent Sensitive): ‘é’ and ‘e’ are considered different.
- AI (Accent Insensitive): ‘é’ and ‘e’ are considered the same.
The choice of collation depends on the requirements of your application. If your application needs case-insensitive and accent-insensitive comparisons, you might choose a collation like Latin1_General_CI_AI. If you need case-sensitive and accent-sensitive comparisons, you might choose Latin1_General_CS_AS
Input Table
| Id | Category | Due_date |
| 1 | To | 2023-02-11 |
| 2 | to | 2024-01-15 |
| 3 | tTo | 2011-05-31 |
| 4 | To | 2023-02-12 |
| 5 | to | 2024-01-17 |
We need to pivot this table on Category, Rows in Category will become columns and have Due date as a value
Direct Approach:
Without using collation, we get this error
Msg 8156, Level 16, State 1, Line 10
The column ‘to’ was specified multiple times for ‘PivotTable’.
Using Collation:
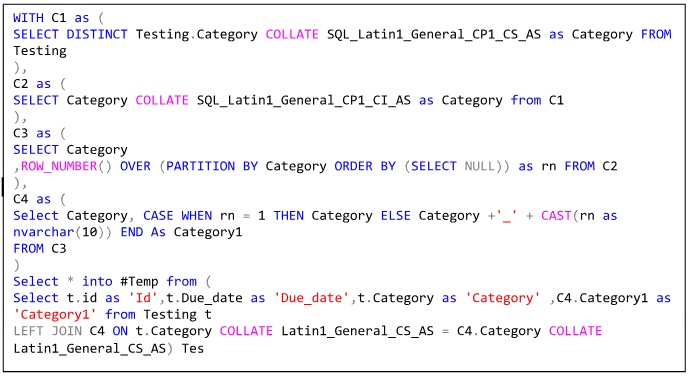
C1: This CTE (C1) selects distinct values from the Category column in the Testing table, applying a case-sensitive collation (SQL_Latin1_General_CP1_CS_AS). The result is a list of unique categories.
C2: This CTE (C2) takes the distinct categories from C1 and applies a case-insensitive collation (SQL_Latin1_General_CP1_CI_AS). This step essentially converts all categories to lowercase for case-insensitive matching.
C3: In this CTE (C3), the ROW_NUMBER() function is used to assign a row number to each category within its partition (based on the category itself). This helps to create a unique identifier for each category.
C4: Here, a new CTE (C4) is created by selecting categories from C3 and using a CASE statement. If the row number (rn) is 1, it keeps the original category; otherwise, it appends an underscore and the row number to create a new identifier (Category1). This is done to handle cases where there are duplicates in the original Category column on case sensitivity.
Select into #Temp: The final part of the query selects data from the Testing table (t) and performs a left join with the C4 CTE based on the original Category column. The join is done with a case-sensitive collation (Latin1_General_CS_AS). The selected columns include id, Due_date, Category, and the newly created Category1 from the C4 CTE. The result of this query is then inserted into a temporary table #Temp.
Next Step is to Dynamically Pivot the Data
This code dynamically generates a pivot query based on the unique values in the Category1 column of the #Temp table and then executes that pivot query to transform the data in #Temp into a pivoted form. The result of the pivot is not explicitly stored or selected; it is executed dynamically.
Output:
| Id | To | to_2 | tTo |
| 1 | 2023-02-12 | NULL | NULL |
| 2 | NULL | 2024-01-17 | NULL |
| 3 | NULL | NULL | 2011-05-31 |
We can see that ‘To’ and ‘to’ are separated columns and we have added ‘_2’ to ‘to’ to uniquely identify both columns.