This blog gives you an overview on how to create data catalogues from RDS MySQL instance using AWS Glue crawler
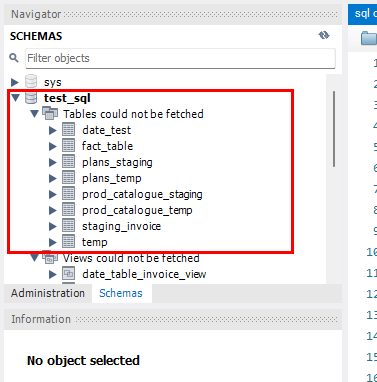
It is assumed that you already have RDS MySQL DB instance running with few tables created in it.
In this blog, MySQL workbench is used to connect with instance database.
Once created the DB with required tables, navigate to AWS Glue console, to create crawler.
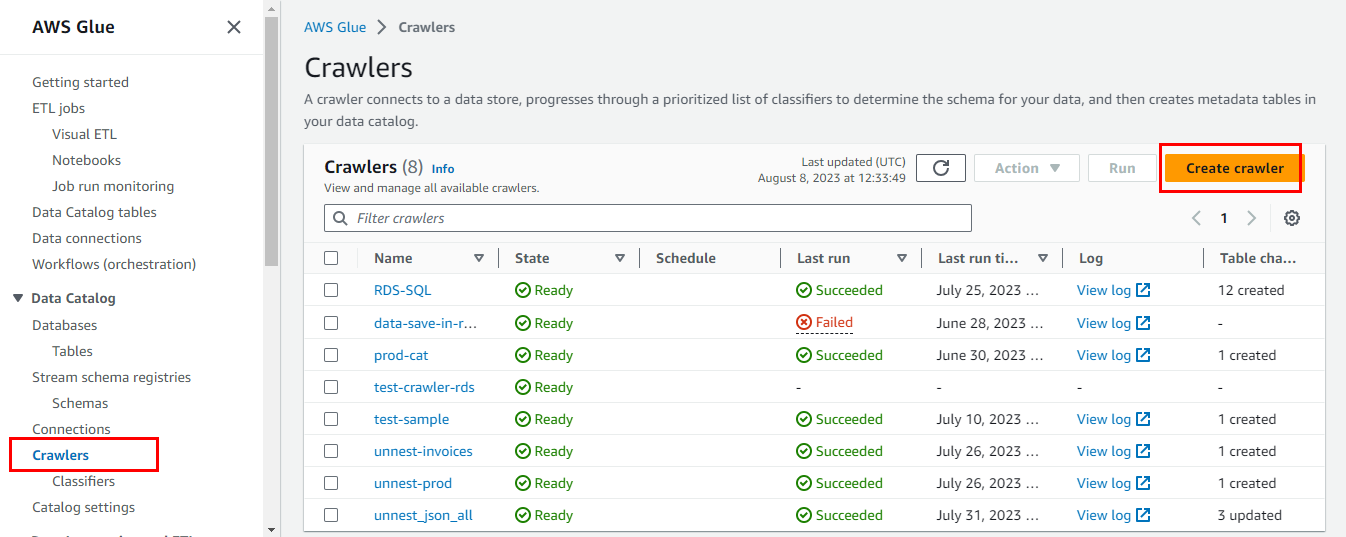
Enter the crawler name, click on next.
In Data Source Configuration, select ‘No’ in ‘Is your data already mapped to Glue tables?’ and click on ‘Add a data source’ .
Enter details as follows.
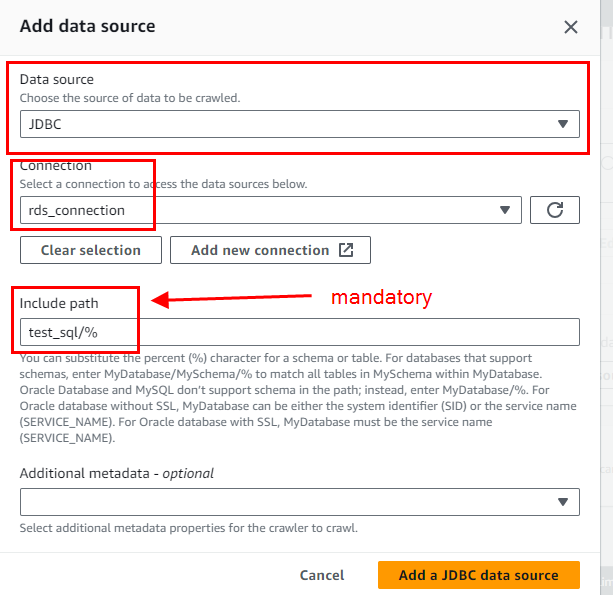
In ‘Include path’, keep ‘schema_name/%’ to crawl all the tables from database. In this example, my schema name is test_sql, click on Next and select the IAM role created from AWS Glue (create a new role, if not created)
Choose the Database created in Data Catalogue. (create a new database, if not created)
Keep the crawler schedule as ‘On Demand’ frequency, click on Next and create a crawler.
Now run the crawler. It takes few minutes to complete its running.
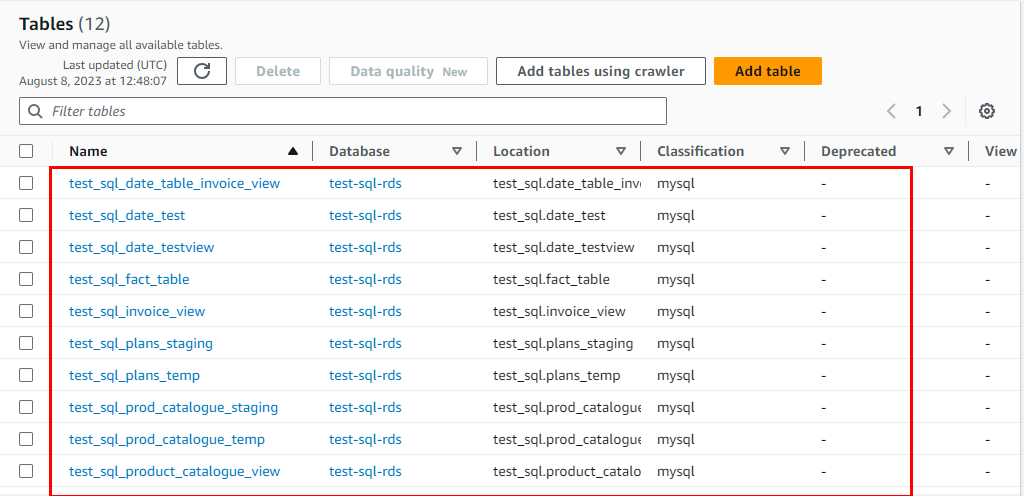
On its successful completion, you can check the tables in Data Catalogues in Database created in Data Catalogue of AWS Glue. There will be same tables as RDS instance in Data Catalogue Database