
Azure Databricks is essentially a management layer built around Apache Spark specifically for big data processing. Azure Databricks, architecturally, is a cloud service that lets you set up and use a cluster of Azure instances with Apache Spark installed.
This is a two-part blog where the first part covers the basics of Databricks which will help you to better understand how Databricks works underneath its simple user interface and the second part dives deep into Databricks where we will create a cluster and write scripts.
Evolution of Databricks
Before we dive deep into Azure Databricks we need to understand what is Databricks as they are two different entities. Let’s go back in time to 2003 when Google released Google File System (GFS) Papers which is a predecessor to the Hadoop File System. Essentially the system involved storing big files in lots of cheap storage disks instead of one big sized storage disk. Google built another system upon this called MapReduce. MapReduce does the same thing for compute operations. It takes on a big compute query, divides it and spreads it up among lots of isolated machines where each of these machines are talking to a cluster manager. Each machine computes the result and gives it back to the cluster manager. MapReduce can drastically speed up big data tasks by breaking down large datasets and processing them in parallel. This concept was further modified and a system was developed called Apache Hadoop. In a nutshell, Apache Hadoop provides a way of storing big data across distributed clusters of servers and then performing distributed analysis across each cluster. Apache formally describes Hadoop as a framework that allows for the distributed processing of large data sets across clusters of computers. It was designed to scale up from a single server to thousands and each machine offering a part of its local computation and storage resources. The framework itself is designed to detect and handle failures rather than relying on hardware. Hence it delivers highly available service on top of a cluster of computers.
The important thing to keep in mind about Hadoop is that it has two main parts – a distributed filesystem for data storage and a data processing framework. There’s more to it than that, but the above two components are the important ones. Hadoop uses the Hadoop Distributed File System (HDFS) for data storage. Although other file systems can be used as well. The data processing framework used to work with the data is the system known as MapReduce (other frameworks can be used too). In a Hadoop cluster, the data stored in HDFS (storage) and the MapReduce (data processing) system are housed on every machine in the cluster. Data and processing live on the same servers in the cluster, every time you add a new machine to the cluster, your distributed system as a whole gain the space of the hard drive and the power of the new processor.
Now that we have understood the basics of Hadoop, let us dive into Spark. Originally developed at UC Berkeley by Matei Zaharia and his colleagues, Spark was first released as an open-source project in 2010. Spark uses the Hadoop MapReduce distributed computing framework as its foundation. The Intention of Spark was to improve several aspects of the MapReduce such as ease of use and performance, while at the same time preserving key benefits of MapReduce.
Spark includes a core data processing engine, as well as libraries for SQL, machine learning, and stream processing. With APIs for Java, Scala, Python, and R, Spark enjoys a wide appeal among developers—earning it the reputation of the “Swiss army knife” of big data processing.
Now the key difference between Spark and Hadoop MapReduce is the approach to data processing. Spark does it in-memory (RAM) and on the other hand, Hadoop MapReduce has to read from and write to a disk. Because of this constant disk read and write, the speed of processing is significant. Spark can be up to 100 times faster. However, when it comes to the volume of data processing Hadoop MapReduce can work with far larger data than Spark. The bottom line is Spark performs better when all the data fits in memory and Hadoop MapReduce is suits better for data that doesn’t fit in memory. If you want to know more about the differences between Spark and Hadoop and the advantages of one over the other, you can check that out in these links (1 , 2)
Now the founders of Spark donated this project to the Apache foundation and now the Spark project came to be known as Apache Spark. Now the question was how people can use this fantastic open-source project. The answer was the formation of a company called Databricks which provided the best and easiest way to work with Apache Spark. And that’s what Databricks is- a management layer built around Spark making it really easy to use. If you want to know in detail about the features that have been added to Apache spark to create Databricks then you can find that here.
The main thing to note is the Databricks Runtime which implements the open-source Apache Spark APIs with a highly optimized execution engine and provides significant performance gains compared to standard open-source Apache Spark. This core engine is then wrapped with many additional services. The takeaway here is that Databricks provides us with an automated cluster management system and IPython style notebooks to code.
So now an obvious question arises- What does Azure has to do with it? The simple answer is when we move Databricks to a Microsoft cloud instance it is called Azure Databricks. Azure Databricks is a jointly developed cloud data service from Microsoft and Databricks for data analytics, data engineering, data science and Machine Learning. It lets you set up and use clusters of Azure instances (or Virtual Machines) with Apache Spark installed. In short, all hardware resources needed for compute comes from Azure cloud and Databricks implements Spark on this cloud hardware for data processing.
Databricks is built for multi-cloud which means Databricks runs on AWS, Microsoft Azure as well as Alibaba cloud. But Azure platform is deeply integrated with Databricks as compared to other cloud platforms. So it would be a wise choice to go with Azure Databricks to get a seamless and streamlined experience of all Azure offerings.
Why Azure Databricks?
Since Azure Databricks is a cloud-based service, it has several advantages over traditional Spark clusters as discussed above. Let us look at some more advantages if you are not convinced yet:
- Optimized spark engine: Data processing with Auto-scaling and spark optimized for up to 50x performance gains.
- Pre-configured environment to support all kinds of data jobs. Frameworks like Pytorch, Tensorflow and sci-kit learn can be installed.
- Integration with MLflow: Track and share experiments, reproduce runs and manage models collaboratively from a central repository.
- Use your preferred language including Python, Scala, R, Spark SQL and .Net
- Collaborative notebook: Quickly access and explore data, find and share new insights and build models collaboratively with languages and tools of your choice.
- Delta Lake: Bring data reliability and scalability to your existing data lake with an open-source transactional storage layer designed for a full data lifecycle.
- Integration with Azure services: Complete your end-to-end analytics and machine learning solution with deep integration with Azure services like Azure Data Factory, Azure Data Lake Storage, Azure Machine Learning and Power BI.
- Interactive workspaces: Easy and seamless coordination between Data Analysts, Data Scientists, Data Engineers and Business Analysts to ensure smooth collaboration.
- Enterprise-Grade Security: The native security provided by Microsoft Azure ensures the protection of data within storage services and private workspaces.
- Production Ready: Easily run, implement and monitor your heavy data-oriented jobs and job-related statistics.
- Databricks Utilities of DBUtils is a Databricks exclusive utility that helps to perform a variety of powerful tasks such as integrating notebooks with Azure Storage, chaining notebooks and work authentication procedures. (Find more about DBUtils here)
Azure Databricks Scenarios
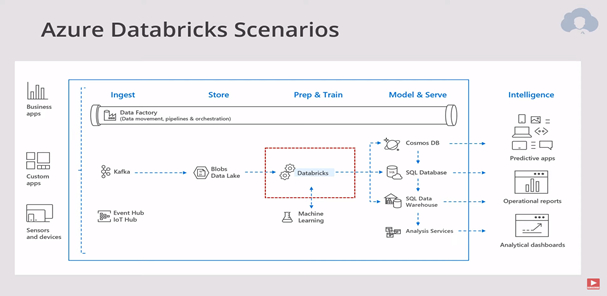
The typical scenario where you would see Databricks is the Prep and Train stage in the Machine Learning pipeline or ETL pipeline. Databricks gives the option to load ingest data from a lot of sources. You can find the list of sources here. One typically loads data from a variety of sources into Azure Blob or Data Lake storage. This is where Databricks come in. Databricks connects to these storage containers and transform the data or use the data to train a Machine Learning model and then export the results to the database as shown in the figure above.
Azure Databricks Pricing
Azure Databricks bills you for virtual machines (VMs) provisioned in clusters and Databricks Units (DBUs). A DBU is a unit of processing capability, billed on per-second usage. The DBU consumption depends on the size and type of instance running Azure Databricks.
Find the detailed pricing information here. Databricks pricing is a little hard to wrap your heads around, so here is another great blog for calculating the price that I found helpful.
In the next part of the blog, I will show you how to create a cluster and write code to integrate a notebook with blob storage.
Mahadevan Iyer,
Data Engineer
Addend Analytics.